前言
对于一些算法题,可以使用Python自带的内置函数解决。但很多时候用就用了,根本不知道内部的细节。这样的话,算时间复杂度**和空间复杂度就很有问题。
因此,我最近几天查阅了网上相关资料,并进行归纳和整理。开始我以为复制粘贴就行了,但是呢,我发现有很多东西都没解释得清楚与透彻,在研读的过程中,我经常很懵逼,更有时候,我都怀疑自己智商了。
最后不得不逼得自己还读了相关源码。越看源码,越发现有很多可以分析的,但是考虑到篇幅和时间,就先打住,以后再整个进阶版。
整理完这个以后,我认为呀,不管什么东西还是得追本溯源,这样才靠谱。
前提说明
时间复杂度是参考官网:
https://wiki.python.org/moin/TimeComplexity
此页面记录了当前CPython中各种操作的时间复杂度(又名“Big O”或“大欧”)。其他Python实现(或CPython的旧版本或仍在开发版本)可能具有略微不同的性能特征。但是, 通常可以安全地假设它们的速度不超过O(log n)。
在所有即将介绍的表格中,n是容器中当前元素的数量,k是参数的值或参数中的元素数。
本文先上结论再进行分析,有助于带着问题去思考答案。
性能总结
1、Python 字典中使用了 hash table,因此查找操作的复杂度为 O(1),而 list 实际是个数组,在 list 中,查找需要遍历整个 list,其复杂度为 O(n),因此对成员的查找访问等操作字典要比 list 更快。
2、set 的 union, intersection,difference 操作要比 list 的迭代要快。因此如果涉及到求 list 交集,并集或者差的问题可以转换为 set 来操作。
3、需要频繁在两端插入或者删除元素,可以选择双端队列。
1、列表(list)
可直接使用,无须调用。
列表实现原理
列表是以数组(Array)实现的,这个数组是 over-allocate 数组。顾名思义,当底层数组容量满了而需要扩充的时候,python依据规则会扩充多个位置出来。比如初始化列表array=[1, 2, 3, 4],向其中添加元素23,此时array对应的底层数组,扩充后的容量不是5,而是8。这就是over-allocate的意义,即扩充容量的时候会多分配一些存储空间。如图1,展示了l.insert(1,5) 的操作。
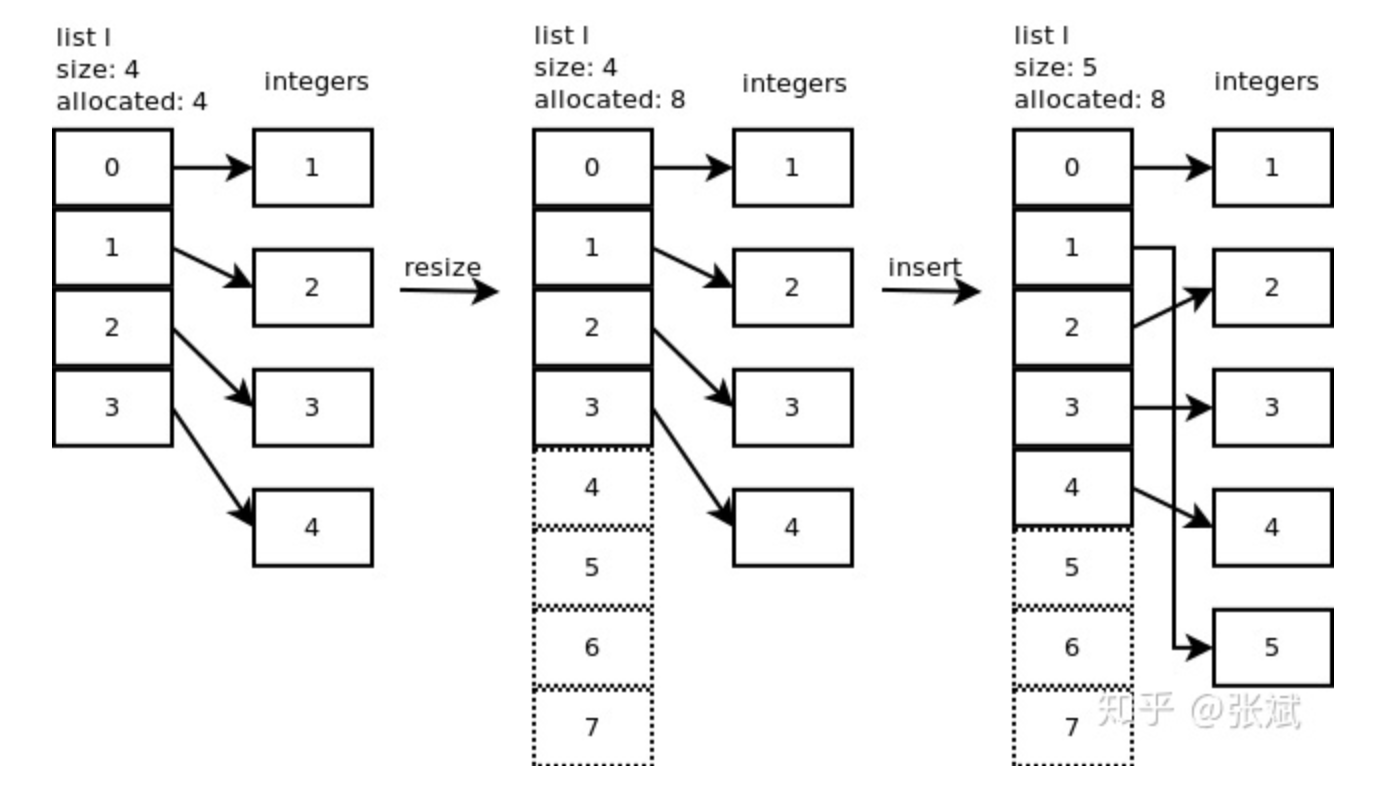
这里说下,列表的增长模式为:0,4,8,16,25,35,46,58,72,88…
列表函数的时间复杂度
如果要更好地理解列表,就必须熟悉数组这种数据结构。如图 2所示,为列表相关函数的时间复杂度。
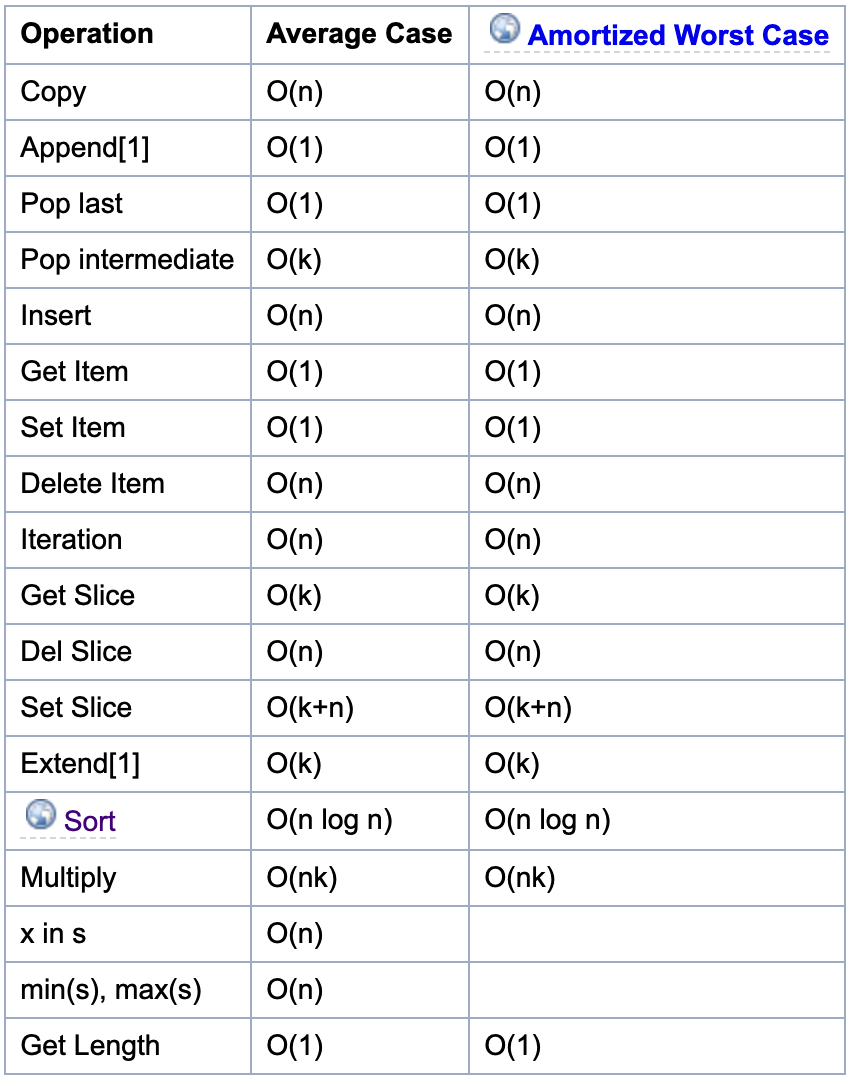
列表函数讲解
- append()方法是指在列表末尾增加一个数据项,这里的表强调的是插入1个元素,即没有扩容。
- extend()方法是指在列表末尾增加一个数据集合;
- insert()方法是指在某个特定位置前面增加一个数据项,需要移动其他元素位置;
- len()方法获取列表内元素的个数,因为在列表实现中,其内部维护了一个
Py_ssize_t类型的变量表示列表内元素的个数,因此时间复杂度为O(1); - sort()方法是排序,网上有原理讲解,使用的是 Timesort 排序,该排序结合了合并排序(merge sort)和插入排序(insertion sort)而得出的排序算法,它在现实中有很好的效率。空间复杂度为O(n)。其排序的过程大致为,对输入的数字进行分区,然后再进行合并;
性能分析
通过对上表的分析可以发现,列表不太适合做元素的查找、删除、插入等操作,因为这些都要遍历列表,对应的时间复杂度为O(n)。
访问某个索引的元素、尾部添加元素(append)或删除(pop last)元素这些操作比较适合用列表做,对应的时间复杂度为O(1)。
根据官方上说,列表最大的开销发生在超过了当前所分配的列表大小,这是因为,所有元素都需要移动;或者是在起始位置附近插入或者删除元素,这种情况下所有在该位置后面的元素都需要移动。如果你需要在一个队列的两端进行增删的操作,应当使用collections.deque。
如果我们要在业务开发中,判断一个value是否在一个数据集中,如果数据集用列表存储,那此时的判断操作就很耗时,如果我们用hash table(set or dict)来存储,则比较轻松。
2、双端队列(collections.deque)
使用时,需要导入:
1 | from collection import deque |
双端队列实现原理
deque(双端队列)是以双向链表的形式实现的。(好吧, 一个数组列表而不是对象, 以提高效率)。
为了更好地理解这种结构,可以参照 GitHub 上 CPython collections 模块的第二个 commit 的源码。注释在文末的附录下面。
这里根据注释,我画了一个不太准确的图,其实leftblock和rightblock都是要存储数据的。但在下图,没有标明。
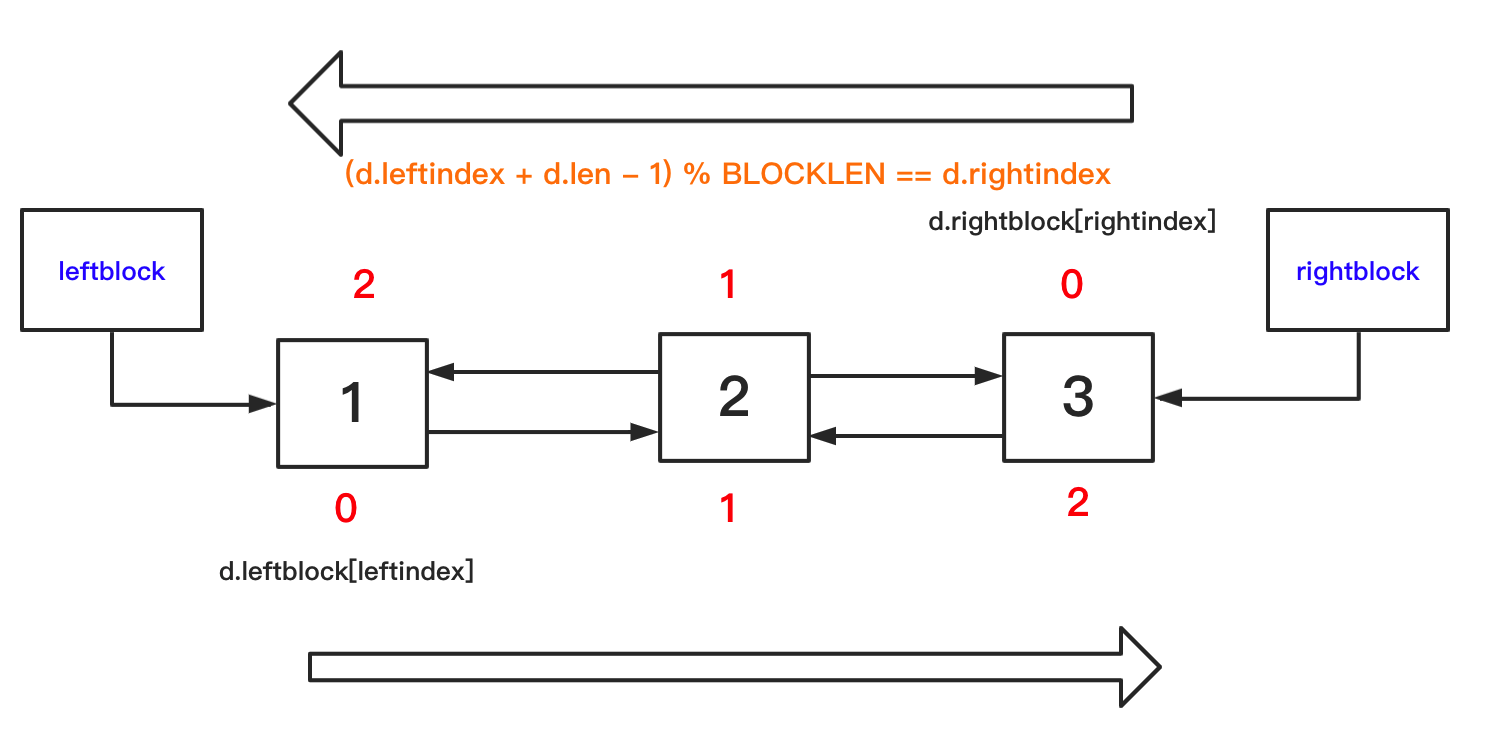
参考资料4,单个block的结构体示意图如下:

总结来说,deque 内部将一组内存块组织成双向链表的形式,每个内存块可以看成一个 Python 对象的数组, 这个数组与普通数据不同,它是从数组中部往头尾两边填充数据,而平常所见数组大都是从头往后。 正因为这个特性,所以叫双端队列。
双端队列时间复杂度
如图所示,为双端队列的相关函数的时间复杂度。
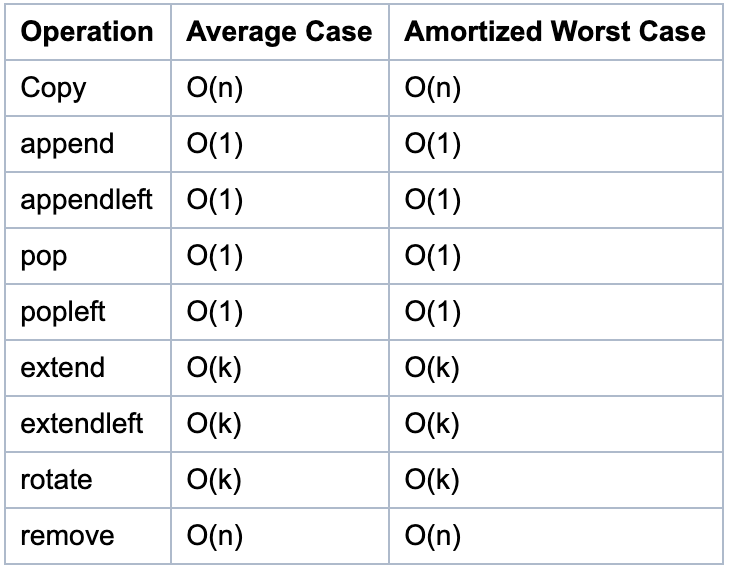
双端队列函数讲解
在这种数据结构下,append方法是怎么实现的呢?
- 如果 rightblock 可以容纳更多的元素,则放在 rightblock 中
- 如果不能,就新建一个 block,然后更新若干指针,将元素放在更新后的 rightblock 中。
性能分析
得益于 deque 这样的结构,它的 pop/popleft/append/appendleft 四种操作的时间复杂度均是 O(1), 用它来实现队列、栈会非常方便和高效。
虽然双端队列中的元素可以从两端弹出,并且队列任意一端都可以入队和出队,但其限定插入和删除操作在表的两端进行。 由于这样,查找双端队列中间的元素较为缓慢, 增删元素就更慢了。
3、字典(dict)
可直接使用,无须调用。
字典实现原理
在Python中,字典是通过哈希表实现的。也就是说,字典是一个数组,而数组的索引是经过哈希函数处理后得到的。要理解字典,必须对哈希表这种数据结构比较熟悉。下图6为哈希表的一个逻辑判断:
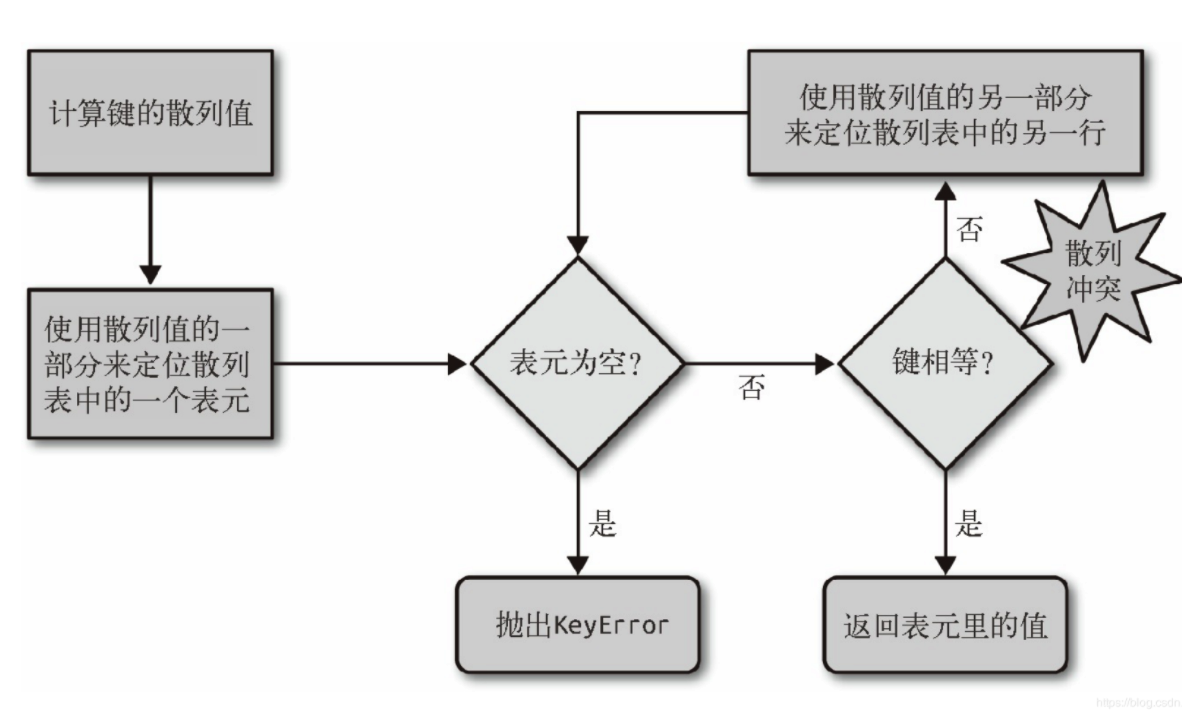
这里要注意几点:
- 使用散列值的一部分进行定位
- 散列冲突时,使用散列值的另一部分,如果这一部分是包含原始Key的信息,那么不同的Key通过比较就能区分出来。
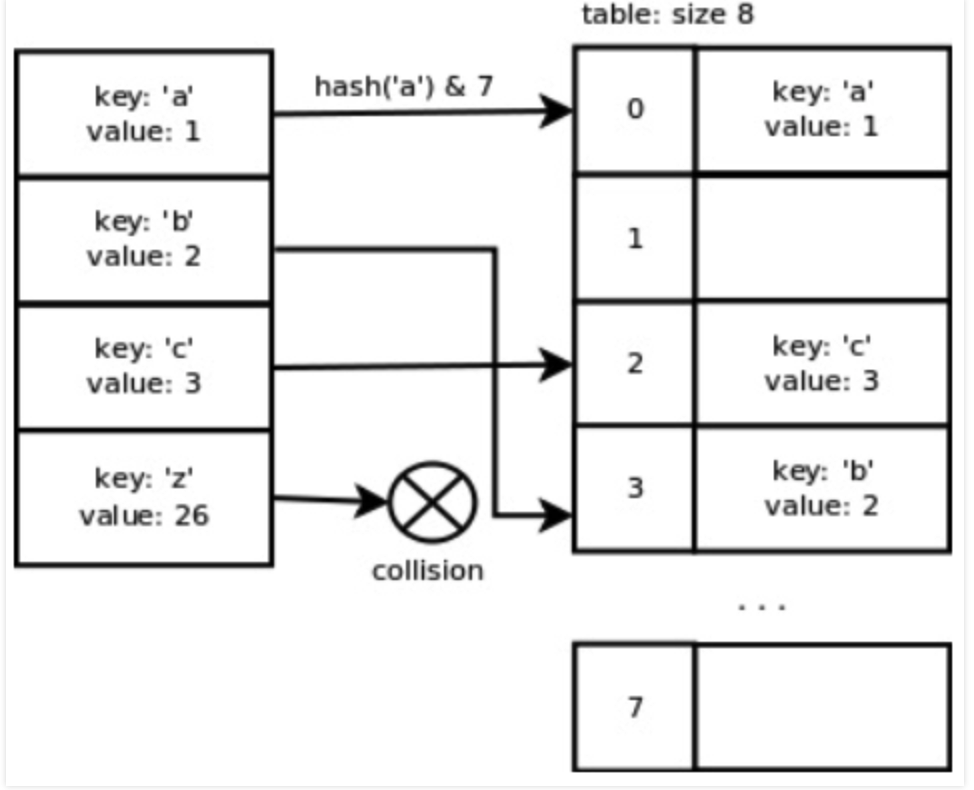
你可能会问,取哈希值的一部分是怎么取得呢?下图7给了一个种方式,就是将计算得到哈希值 & 数组的长度。
同时,由这张图,我们可以发现Python的哈希函数在键彼此连续的时候表现得很理想,这主要是考虑到通常情况下处理的都是这类形式的数据。然而,一旦我们添加了键’z’就会出现冲突,因为这个键值并不毗邻其他键,且相距较远。
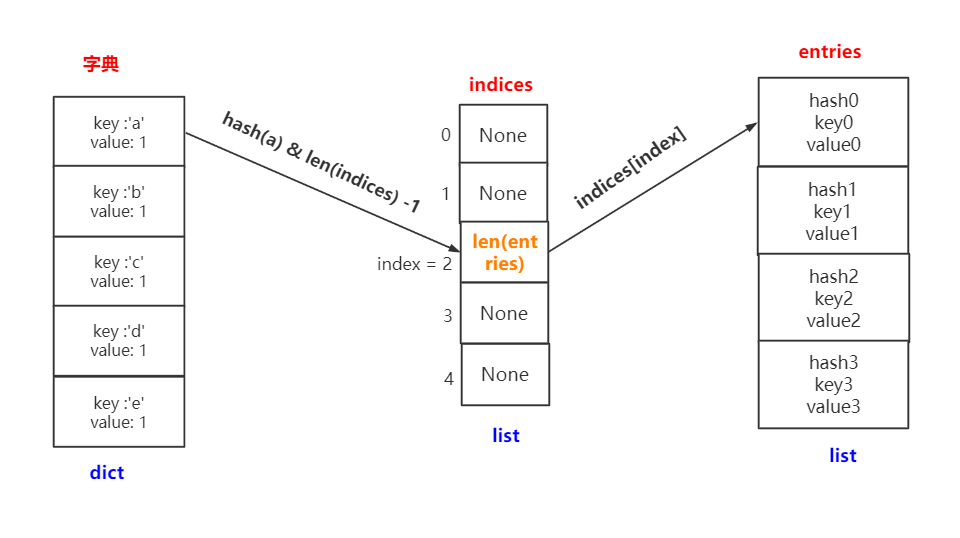
先要声明的是,针对python的不同版本,dict的实现还有所不同,较为详细的介绍请参考资料[6]。老字典只使用一张hash,而新字典还使用了一张Indices表来辅助。这里的indices才是真正的散列表哦,下来列出新的结构:
1 | indices = [None, None, index, None, index, None, index] |
字典存储过程:
- 计算key的hash值 (
hash(key)),再和mask做与操作 (mask=字典最小长度(IndicesDictMinSize)- 1),运算后会得到一个数字index,这个index就是要插入的indices的下标位置(注:具体算法与Python版本相关,并不一定一样); - 得到index后,会找到indices的位置,但是此位置不是存的hash值,而是存的
len(enteies),表示该值在enteies中的位置; - 如果出现hash冲突,则会继续向下寻找空位置(略有变化的开放寻址),一直到找到剩余空位为止。
字典查找过程:
- 计算 hash(key),得到hash_value ;
- 计算
hash_value & ( len(indices) - 1),得到一个数字index ; - 计算 indices[index] 的值,得到 entry_index ;
- 计算 enteies[entey_index] 的值 ,为最终值。
为方便理解,这里我做了一个图,可以看到 indices 起到一个桥梁的作用。画完这个图,再感叹一句,设计还是挺巧妙的。
这里补充下,关于哈希冲突,是怎么寻找下一个数组位置的。源码中用到的是以下公式:
1 | j = ((5*j) + 1) mod 2**i |
这里的 j 有两层含义,赋值号左边的为数组的下一个下标,赋值号右边的是当前发生冲突的下标。而 2 ** i可以理解数组长度。举例说明,对于要给size大小为2 ** 3来说:
1 | j_prev = 0 ; j_next = ((5 * 0) + 1) mod 8 = 1 |
以此类推,最后回到起点为0。以下就是哈希冲突的轨迹
0 -> 1 -> 6 -> 7 -> 4 -> 5 -> 2 -> 3 -> 0 [and here it’s repeating]
字典函数的时间复杂度
下列字典的平均情况基于以下假设:
- 对象的散列函数足够撸棒(robust), 不会发生冲突。
- 字典的键是从所有可能的键的集合中随机选择的。
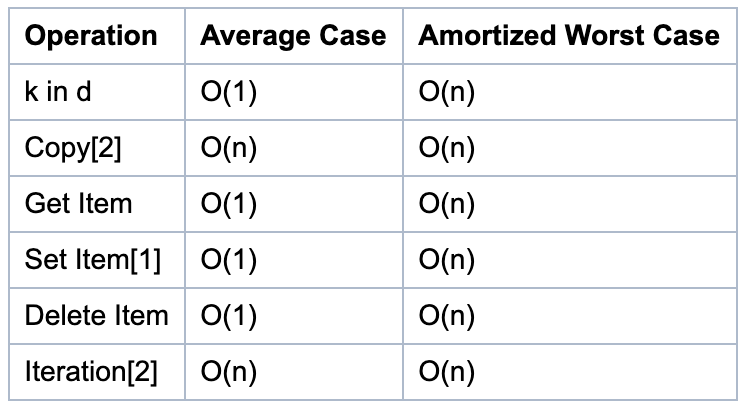
小窍门:只使用字符串作为字典的键。这么做虽然不会影响算法的时间复杂度, 但会对常数项产生显著的影响, 这决定了你的一段程序能多快跑完。
字典函数说明
- 这些操作依赖于“摊销最坏情况”的“摊销”部分。根据容器的历史, 个别动作可能需要很长时间。
- 对于这些操作, 最坏的情况n是容器达到的最大尺寸, 而不仅仅是当前的大小。例如, 如果一个N个元素的字典, 然后删除N-1个元素, 这个字典会重新为N个元素调整大小, 而不是当前的一个元素, 所以时间复杂度是O(n)。
字典性能分析
字典的查询、添加、删除的平均时间复杂度都是O(1),相比列表与元祖,性能更优。但是,如果发生散列冲突,或者容器需要扩充,那么时间复杂度就要考虑最差的情况 O(n)。所以说字典及其依赖哈希算法,真正要灵活运用词典时,还需要查看底层的哈希算法。
4、集合(set)
dict与set实现原理是一样的,都是将实际的值放到list中。唯一不同的在于hash函数操作的对象,对于dict,hash函数操作的是其key,而对于set是直接操作的它的元素。
假设操作内容为x,其作为因变量,放入hash函数,通过运算后取list的余数,转化为一个list的下标,此下标位置对于set而言用来放其本身。
而对于dict则是创建了两个list,一个listf存储哈希表对应的下标,另一个list中存储哈希表具体对应的值。
这里为了更好地理解,对比上面字典那个图,我尝试画一个图。
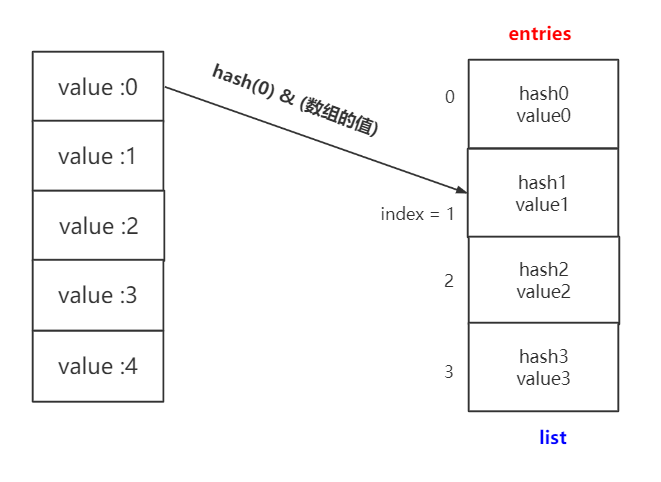
集合函数的时间复杂度
下图是函数的时间复杂度:
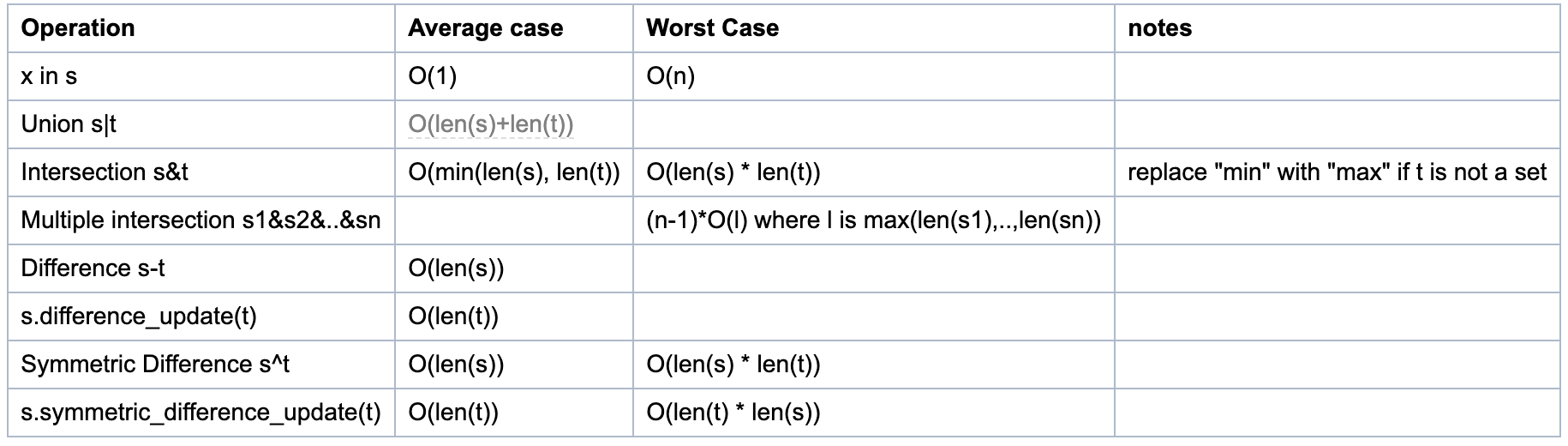
集合性能分析
由源码得知, 求差集(s-t, 或s.difference(t))运算与更新为差集(s.difference_uptate(t))运算的时间复杂度并不相同!
- 第一个是O(len(s))(对于s中的每个元素, 如果不在t中, 将它添加到新集合中)。
- 第二个是O(len(t))(对于t中的每个元素, 将其从s中删除)。
因此, 必须注意哪个是首选, 取决于哪一个是最长的集合以及是否需要新的集合。
集合的s-t运算中, s和t都要是set类型。如果t不是set类型, 但是是可迭代的, 你可以使用等价的方法达到目的, 比如 s.difference(l), l是个list类型。
另外,列表的一些集合运算,可以转成集合类型来操作,速度更快。
给自己留一个坑
自己也尝试读了一下一些数据结构的源码,虽然很多看不懂,但是抓到一些关键信息。比如下面的代码和图片。
1 | static Py_ssize_t |
下图12为dictobject.c里的一个函数:
参考资料
[1] Python内置方法的时间复杂度
[2] TimeComplexity
[4] How collections.deque works?,
[5] 深入 Python 列表的内部实现;
[6] Python字典dict实现原理
附录
Cpython list 部分源码注释
源码地址传送门:
https://github.com/python/cpython/blob/master/Objects/listobject.c
1 | /* This over-allocates proportional to the list size, making room |
Cpython collections 部分源码注释
源码地址传送门:
https://github.com/python/cpython/blob/master/Modules/_collectionsmodule.c
1 | /* The block length may be set to any number over 1. Larger numbers |
Cpython dict源码部分注释
源码地址传送门:
https://github.com/python/cpython/blob/master/Objects/dictobject.c
1 | /*layout: |